Most often our personalities and souls are written into pages of diaries, texts, academic papers etc. The work I write is also an example of that. The probability that the letters predicted as I write depends on the frequency and language I chose to write. For example:
Sul: sup dude
Sul LLM:
"p" and "d" is more likely to show up next "u" than other letters.So if we take this type of philosophy into account we can start to believe that certain LLMs can be specialized agents for different academic resources. For example Pihkal:

Let’s create an OpenAPI account:

And create an API secret key by clicking API keys on the left hand sidebar and creating a new secret key:

Let’s get our python imports going:
# Imports
# -------
import os
# Langchain Imports
# -----------------
from langchain.llms import OpenAI
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from langchain.document_loaders import PyPDFDirectoryLoaderNext let’s develop a class object that will be our “Shulgin”, we want to do two things.
- ) Create a loader which loads the document into a python variable.
- ) Create a word embeddings which vectorizes the the letters and creates a probablity distribution.
class ShulginLLM(object):
__OPEN_API_KEY__ = 'YOUR_OPENAPI_KEY'
def __init__(self):
self.agent = None
self.loader = self.load_node()
self.create_word_embeddings_and_conversations()Add your OpenAPI Key and initialize the class. Next then load the node. You will have to find your version of the shulgin book
def load_node(self):
loader = PyPDFDirectoryLoader("PATH_DIRECTORY_FOR_BOOK")
text_loader = loader.load()
return text_loaderThen create the embeddings:
def create_word_embeddings_and_conversations(self):
'''
Create the Vector Database for Word Embeddings
'''
embeddings = OpenAIEmbeddings(openai_api_key=self.__OPEN_API_KEY__)
vectordb = Chroma.from_documents(
self.loader,
embedding=embeddings,
persist_directory="."
)
vectordb.persist()
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = ConversationalRetrievalChain.from_llm(
OpenAI(temperature=0.8, openai_api_key=self.__OPEN_API_KEY__),
vectordb.as_retriever(),
memory=memory,
max_tokens_limit=4000
)
self.agent = conversationLet’s break down what is going on here. The first line:
embeddings = OpenAIEmbeddings(openai_api_key=self.__OPEN_API_KEY__)creates the text similarity between batches of text. The Chroma is a way to store the data so it’s fast for retrieval when processing large amounts of text. Persist the database priming it to drop objects that are unecessary. I believe this would be useful for as the conversation continues if words are not used anymore we can drop it.
vectordb.persist()This is where the real meat happens where we store the conversation of chats back and forth in messages:
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = ConversationalRetrievalChain.from_llm(
OpenAI(temperature=0.8, openai_api_key=self.__OPEN_API_KEY__),
vectordb.as_retriever(),
memory=memory,
max_tokens_limit=4000
)
self.agent = conversationWhat’s going on here is that the we want to store the retrieval of messages and then countinuously update the chromadb
Set the max token limit in how much can get return and now we want a function that is
def run_question(self, question=''):
answer = self.agent({"question": question})
return answer['answer']Execute a question to shulgin to synthesize 2CI:
if __name__ == '__main__':
shulgin_llm = ShulginLLM()
answer = shulgin_llm.run_question(
question='how to synthesize 2-(4-Iodo-2,5-dimethoxyphenyl)ethan-1-amine?'
)
print (answer)And here we go:
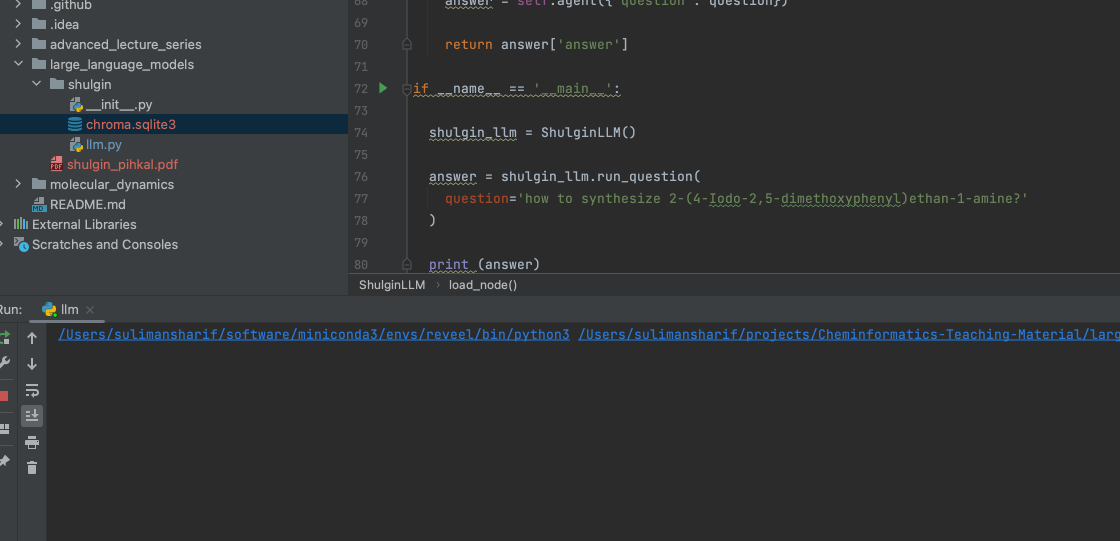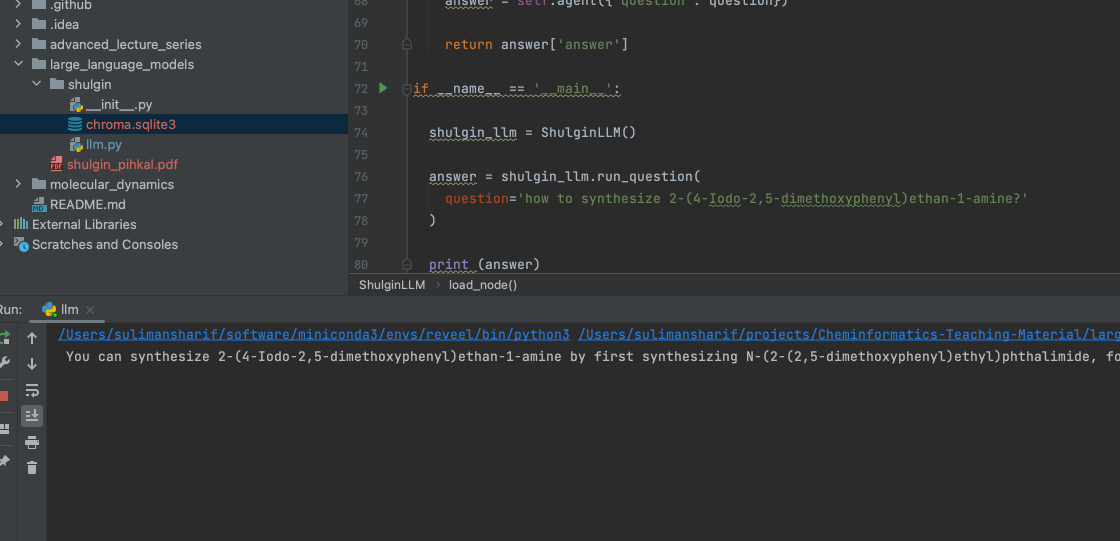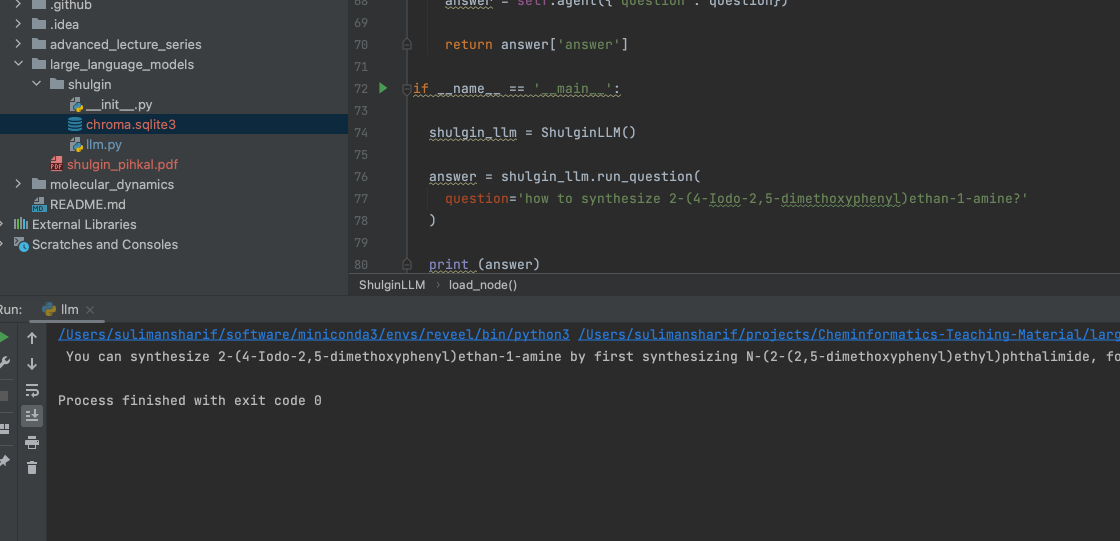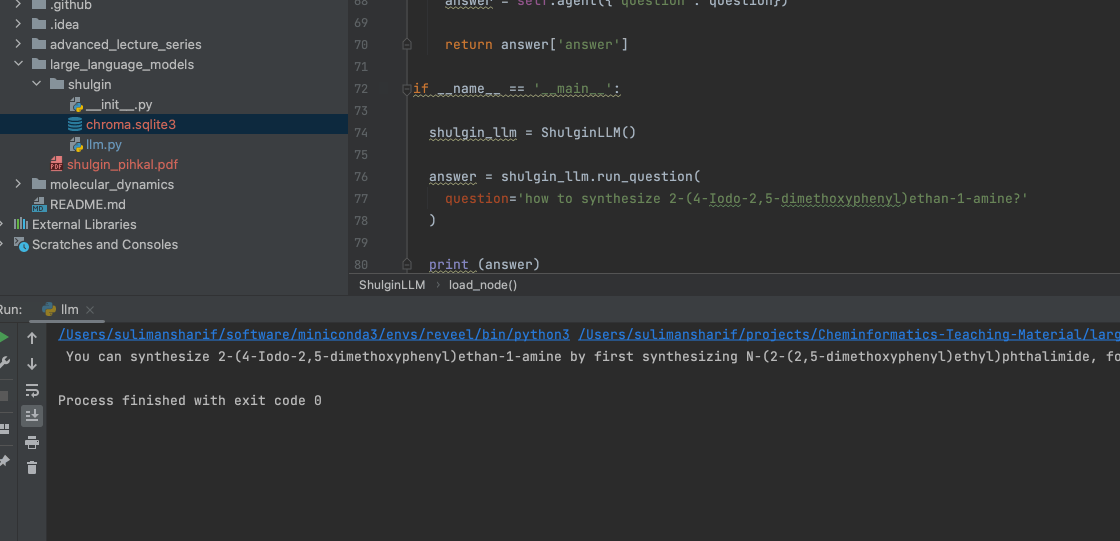
Next we can implement something more hardcore to see how it works. Happy Cheminformatics!
