Chemical Diversity is hard to define, and for a list of SMILES it can be ever increasing to understand what that really means. Fingerprinting is alternative method of converting a SMILES into a bit representation that has different features of that chemical compound. Unfortunately, when the conversion happens we lose information of a readable human molecule and perhaps something worthwhile so we can make understanding of it.
Other efforts to “decode” fingerprinting to gain some understanding in a chemical dataset are proving to be cumbersome and won’t scale as the in-silico chemical universe expands.So what do we do? Well lets return to an old human language designed to capture chemical environments in a language we all understand, “english”. Thus drove the motive for designing GlobalChem

Philosophy
IUPAC was designed to have some form of structure for chemical nomenclature and overtime it expanded into a more“preferred” names, or “slang” if you will, overtime this dataset about how different IUPAC names related to different communities grew to be enormous with reported information about compound tied to their name but scattered. I designed `GlobalChem` for this intended purpose to find chemical diversity. To browse how your initial dataset we will use a data visualization method called “Sunbursting”. An old method used to visualize high sets of data and their respective categories.

Algorithm
The purpose of the algorithm is to highlight a functional group and a relational functional group of each compound and their respective count within the list of molecules. The algorithm to determine the layers is very simple. Take phenol:
C1=CC=CC=C1ONow the algorithm looks through GlobalChem and determines functional group matches which I would assume to be:
benzene
phenol
alcoholIt then takes the longest name and the shortest name, presumably if something is more longer it captures more information and if something is smaller it captures less. This tends to not hold for IUPAC nomenclature < 20 letters long arbitrarily but in our specific case it works out.
benzene-phenolSo the first layer would show a count for
First Layer: benzene
Second Layer: benzene-phenolDoesn’t seem like much but let’s say we want to tell the diversity in 10,000 molecules. What could we do?
Code
Install:
pip install global-chem[cheminformatics]Import:
from global_chem import GlobalChem
from global_chem_extensions import GlobalChemExtensionsgc = GlobalChem()
gc.build_global_chem_network()
cheminformatics = GlobalChemExtensions().cheminformatics()
Sunburst:
gc = GlobalChem()smiles_list =
list(gc.get_node_smiles('emerging_perfluoroalkyls').values())sunburster = cheminformatics.sunburst_chemical_list(
smiles_list
)sunburster.sunburst()
And that’s it. You can pass in any list of chemical SMILES and we can use sunbursting with IUPAC to check it’s diversity. Happy Drug Hunting!
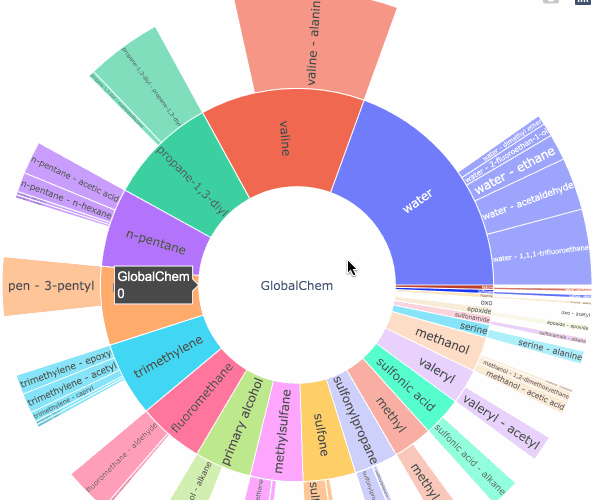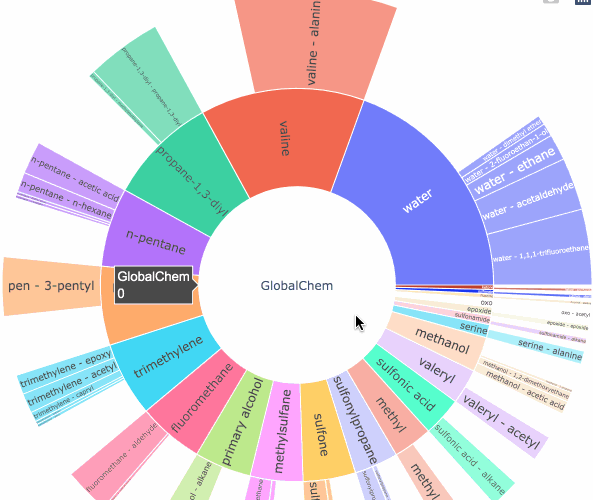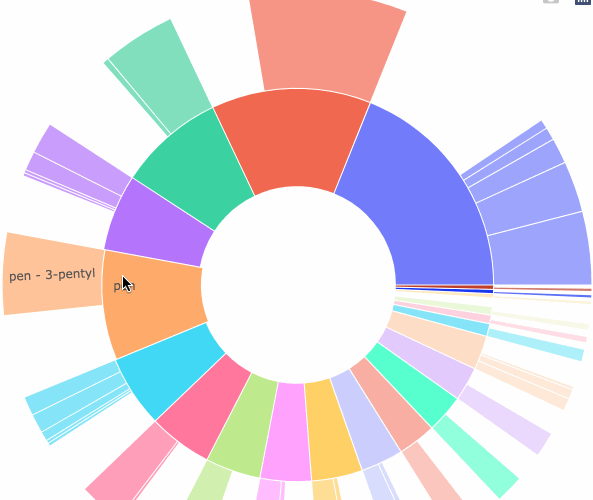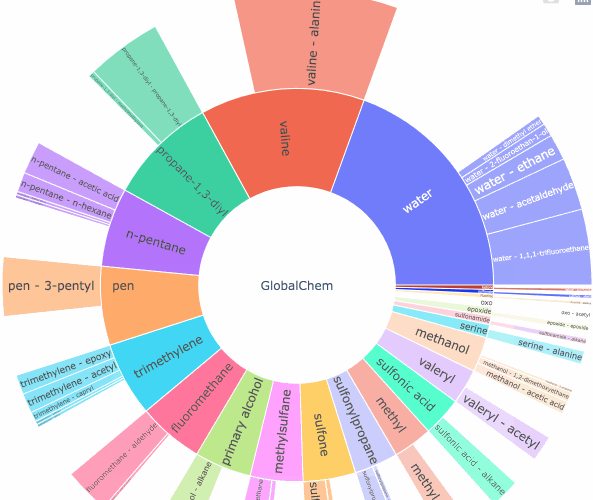
Demo:
